

| Overview:
|
1. Definitions:
Statistic - A characteristic or measure obtained by using the data values from a sample (This is usually denoted by ROMAN letters)
When I say "ROMAN" letters, I mean "A,B,C,D, etc."
Parameter - A characteristic or measure obtained by using the data values from a population (This is usually denoted by GREEK letters)
When I say "GREEK" letters, I mean (see below):
2. THE GREEK ALPHABET (abbreviated)
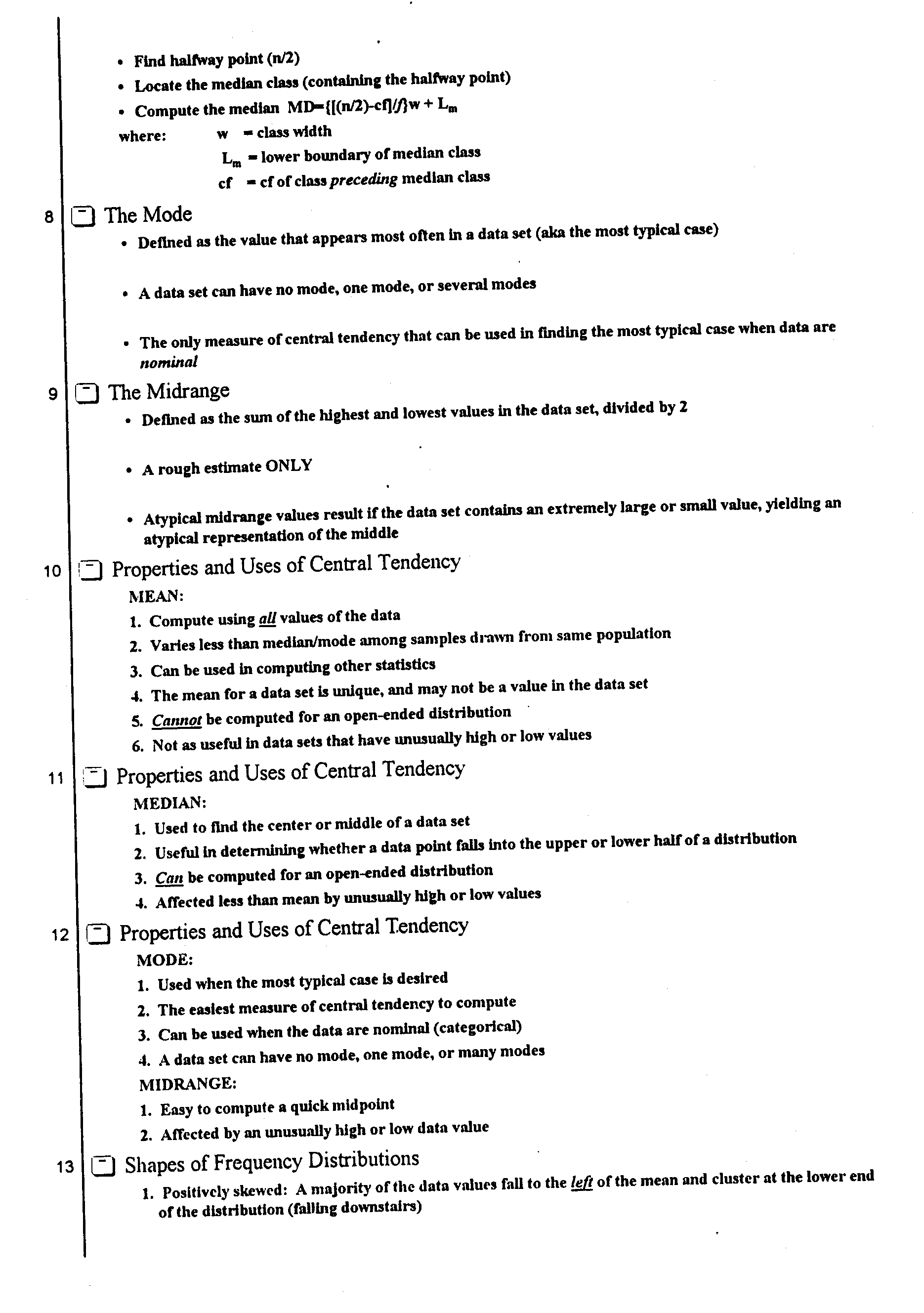
| Greek Letter
Upper and lower case |
Spoken as (in English): | Special Meaning
(in Math): |
Roman Letter equivalent: |
| A,a | "ALPHA" | A,a | |
| W,w | "OMEGA" ("O-MAY-GAH") | O,o | |
| B,b | "BETA" ("BAY-TAH") | B,b | |
| G,g | "GAMMA" | G,g | |
| D,d | "DELTA" | Expresses a change in a quantity | D,d |
| E,e | "EPSILON" | E,e | |
| P,p | "PI" | Either "Multipication", or
the special number in geometry "3.1415~" |
P,p |
| S,s | "SIGMA" | Addition | S,s |
| Q,q | "THETA" ("THAY-TAH") | Geometric Angle | Th (as in "the") |
These are just a few. There are
These symbols may seem strange, but the SIGMA will be VERY important,
as you will see soon.
Measures of Central Tendency
The basic idea here is that, in a given data set, we want to know where the "middle of the pack" is located. There are four different ways to do this. They are:
| HOMEWORK:
Read Chapter 3 in the textbook
|